The Go Blog
Experiment, Simplify, Ship
Introduction
This is the blog post version of my talk last week at GopherCon 2019.
We are all on the path to Go 2, together, but none of us know exactly where that path leads or sometimes even which direction the path goes. This post discusses how we actually find and follow the path to Go 2. Here’s what the process looks like.
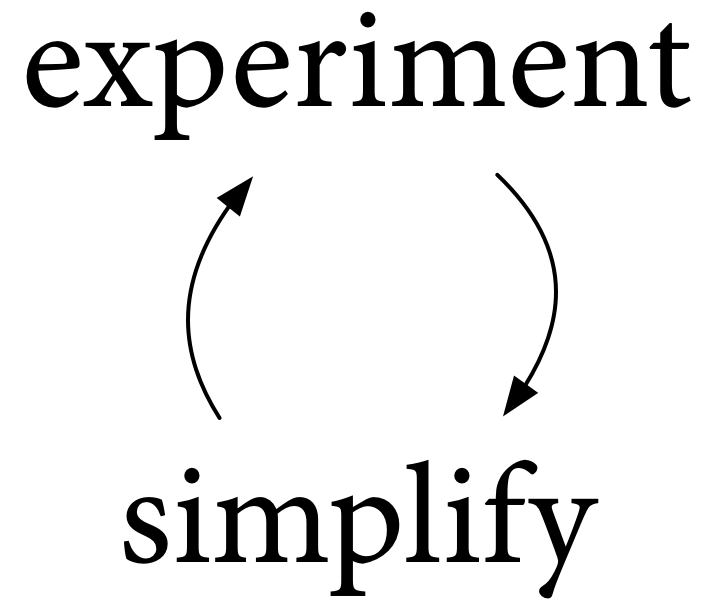
We experiment with Go as it exists now, to understand it better, learning what works well and what doesn’t. Then we experiment with possible changes, to understand them better, again learning what works well and what doesn’t. Based on what we learn from those experiments, we simplify. And then we experiment again. And then we simplify again. And so on. And so on.
The Four R’s of Simplifying
During this process, there are four main ways that we can simplify the overall experience of writing Go programs: reshaping, redefining, removing, and restricting.
Simplify by Reshaping
The first way we simplify is by reshaping what exists into a new form, one that ends up being simpler overall.
Every Go program we write serves as an experiment to test Go itself.
In the early days of Go, we quickly learned that
it was common to write code like this addToList function:
func addToList(list []int, x int) []int {
n := len(list)
if n+1 > cap(list) {
big := make([]int, n, (n+5)*2)
copy(big, list)
list = big
}
list = list[:n+1]
list[n] = x
return list
}
We’d write the same code for slices of bytes, and slices of strings, and so on. Our programs were too complex, because Go was too simple.
So we took the many functions like addToList in our programs
and reshaped them into one function provided by Go itself.
Adding append made the Go language a little more complex,
but on balance
it made the overall experience of writing Go programs simpler,
even after accounting for the cost of learning about append.
Here’s another example. For Go 1, we looked at the very many development tools in the Go distribution, and we reshaped them into one new command.
5a 8g
5g 8l
5l cgo
6a gobuild
6cov gofix → go
6g goinstall
6l gomake
6nm gopack
8a govet
The go command is so central now that
it is easy to forget that we went so long without it and how much extra work that involved.
We added code and complexity to the Go distribution, but on balance we simplified the experience of writing Go programs. The new structure also created space for other interesting experiments, which we’ll see later.
Simplify by Redefining
A second way we simplify is by redefining functionality we already have, allowing it to do more. Like simplifying by reshaping, simplifying by redefining makes programs simpler to write, but now with nothing new to learn.
For example, append was originally defined to read only from slices.
When appending to a byte slice, you could append the bytes from another byte slice,
but not the bytes from a string.
We redefined append to allow appending from a string,
without adding anything new to the language.
var b []byte
var more []byte
b = append(b, more...) // ok
var b []byte
var more string
b = append(b, more...) // ok later
Simplify by Removing
A third way we simplify is by removing functionality when it has turned out to be less useful or less important than we expected. Removing functionality means one less thing to learn, one less thing to fix bugs in, one less thing to be distracted by or use incorrectly. Of course, removing also forces users to update existing programs, perhaps making them more complex, to make up for the removal. But the overall result can still be that the process of writing Go programs becomes simpler.
An example of this is when we removed the boolean forms of non-blocking channel operations from the language:
ok := c <- x // before Go 1, was non-blocking send
x, ok := <-c // before Go 1, was non-blocking receive
These operations were also possible to do using select,
making it confusing to need to decide which form to use.
Removing them simplified the language without reducing its power.
Simplify by Restricting
We can also simplify by restricting what is allowed. From day one, Go has restricted the encoding of Go source files: they must be UTF-8. This restriction makes every program that tries to read Go source files simpler. Those programs don’t have to worry about Go source files encoded in Latin-1 or UTF-16 or UTF-7 or anything else.
Another important restriction is gofmt for program formatting.
Nothing rejects Go code that isn’t formatted using gofmt,
but we have established a convention that tools that rewrite Go programs
leave them in gofmt form.
If you keep your programs in gofmt form too,
then these rewriters don’t make any formatting changes.
When you compare before and after,
the only diffs you see are real changes.
This restriction has simplified program rewriters
and led to successful experiments like
goimports, gorename, and many others.
Go Development Process
This cycle of experiment and simplify is a good model for what we’ve been doing the past ten years. but it has a problem: it’s too simple. We can’t only experiment and simplify.
We have to ship the result. We have to make it available to use. Of course, using it enables more experiments, and possibly more simplifying, and the process cycles on and on.
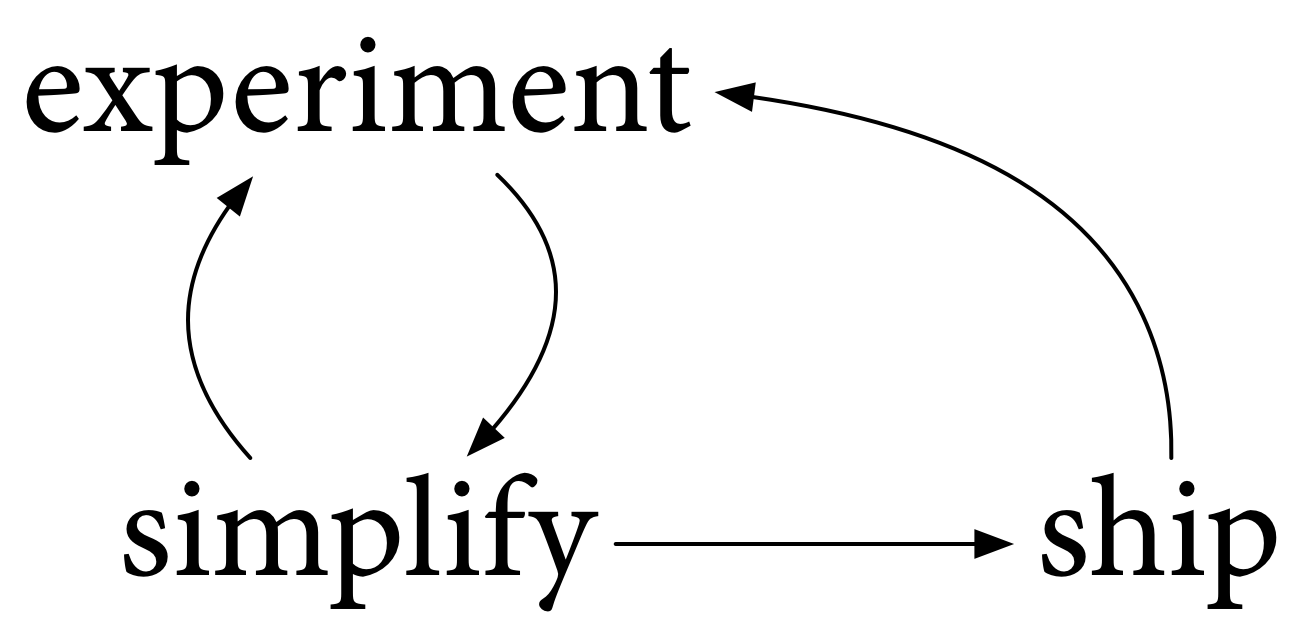
We shipped Go to all of you for the first time on November 10, 2009. Then, with your help, we shipped Go 1 together in March 2012. And we’ve shipped twelve Go releases since then. All of these were important milestones, to enable more experimentation, to help us learn more about Go, and of course to make Go available for production use.
When we shipped Go 1, we explicitly shifted our focus to using Go, to understand this version of the language much better before trying any more simplifications involving language changes. We needed to take time to experiment, to really understand what works and what doesn’t.
Of course, we’ve had twelve releases since Go 1, so we have still been experimenting and simplifying and shipping. But we’ve focused on ways to simplify Go development without significant language changes and without breaking existing Go programs. For example, Go 1.5 shipped the first concurrent garbage collector and then the following releases improved it, simplifying Go development by removing pause times as an ongoing concern.
At Gophercon in 2017, we announced that after five years of experimentation, it was again time to think about significant changes that would simplify Go development. Our path to Go 2 is really the same as the path to Go 1: experiment and simplify and ship, towards an overall goal of simplifying Go development.
For Go 2, the concrete topics that we believed were most important to address are error handling, generics, and dependencies. Since then we have realized that another important topic is developer tooling.
The rest of this post discusses how our work in each of these areas follows that path. Along the way, we’ll take one detour, stopping to inspect the technical detail of what will be shipping soon in Go 1.13 for error handling.
Errors
It is hard enough to write a program that works the right way in all cases when all the inputs are valid and correct and nothing the program depends on is failing. When you add errors into the mix, writing a program that works the right way no matter what goes wrong is even harder.
As part of thinking about Go 2, we want to understand better whether Go can help make that job any simpler.
There are two different aspects that could potentially be simplified: error values and error syntax. We’ll look at each in turn, with the technical detour I promised focusing on the Go 1.13 error value changes.
Error Values
Error values had to start somewhere.
Here is the Read function from the first version of the os package:
export func Read(fd int64, b *[]byte) (ret int64, errno int64) {
r, e := syscall.read(fd, &b[0], int64(len(b)));
return r, e
}
There was no File type yet, and also no error type.
Read and the other functions in the package
returned an errno int64 directly from the underlying Unix system call.
This code was checked in on September 10, 2008 at 12:14pm. Like everything back then, it was an experiment, and code changed quickly. Two hours and five minutes later, the API changed:
export type Error struct { s string }
func (e *Error) Print() { … } // to standard error!
func (e *Error) String() string { … }
export func Read(fd int64, b *[]byte) (ret int64, err *Error) {
r, e := syscall.read(fd, &b[0], int64(len(b)));
return r, ErrnoToError(e)
}
This new API introduced the first Error type.
An error held a string and could return that string
and also print it to standard error.
The intent here was to generalize beyond integer codes. We knew from past experience that operating system error numbers were too limited a representation, that it would simplify programs not to have to shoehorn all detail about an error into 64 bits. Using error strings had worked reasonably well for us in the past, so we did the same here. This new API lasted seven months.
The next April, after more experience using interfaces,
we decided to generalize further
and allow user-defined error implementations,
by making the os.Error type itself an interface.
We simplified by removing the Print method.
For Go 1 two years later,
based on a suggestion by Roger Peppe,
os.Error became the built-in error type,
and the String method was renamed to Error.
Nothing has changed since then.
But we have written many Go programs,
and as a result we have experimented a lot with how
best to implement and use errors.
Errors Are Values
Making error a simple interface
and allowing many different implementations
means we have the entire Go language
available to define and inspect errors.
We like to say that errors are values,
the same as any other Go value.
Here’s an example.
On Unix,
an attempt to dial a network connection
ends up using the connect system call.
That system call returns a syscall.Errno,
which is a named integer type that represents
a system call error number
and implements the error interface:
package syscall
type Errno int64
func (e Errno) Error() string { ... }
const ECONNREFUSED = Errno(61)
... err == ECONNREFUSED ...
The syscall package also defines named constants
for the host operating system’s defined error numbers.
In this case, on this system, ECONNREFUSED is number 61.
Code that gets an error from a function
can test whether the error is ECONNREFUSED
using ordinary value equality.
Moving up a level,
in package os,
any system call failure is reported using
a larger error structure that records what
operation was attempted in addition to the error.
There are a handful of these structures.
This one, SyscallError, describes an error
invoking a specific system call
with no additional information recorded:
package os
type SyscallError struct {
Syscall string
Err error
}
func (e *SyscallError) Error() string {
return e.Syscall + ": " + e.Err.Error()
}
Moving up another level,
in package net,
any network failure is reported using an even
larger error structure that records the details
of the surrounding network operation,
such as dial or listen,
and the network and addresses involved:
package net
type OpError struct {
Op string
Net string
Source Addr
Addr Addr
Err error
}
func (e *OpError) Error() string { ... }
Putting these together,
the errors returned by operations like net.Dial can format as strings,
but they are also structured Go data values.
In this case, the error is a net.OpError, which adds context
to an os.SyscallError, which adds context to a syscall.Errno:
c, err := net.Dial("tcp", "localhost:50001")
// "dial tcp [::1]:50001: connect: connection refused"
err is &net.OpError{
Op: "dial",
Net: "tcp",
Addr: &net.TCPAddr{IP: ParseIP("::1"), Port: 50001},
Err: &os.SyscallError{
Syscall: "connect",
Err: syscall.Errno(61), // == ECONNREFUSED
},
}
When we say errors are values, we mean both that the entire Go language is available to define them and also that the entire Go language is available to inspect them.
Here is an example from package net.
It turns out that when you attempt a socket connection,
most of the time you will get connected or get connection refused,
but sometimes you can get a spurious EADDRNOTAVAIL,
for no good reason.
Go shields user programs from this failure mode by retrying.
To do this, it has to inspect the error structure to find out
whether the syscall.Errno deep inside is EADDRNOTAVAIL.
Here is the code:
func spuriousENOTAVAIL(err error) bool {
if op, ok := err.(*OpError); ok {
err = op.Err
}
if sys, ok := err.(*os.SyscallError); ok {
err = sys.Err
}
return err == syscall.EADDRNOTAVAIL
}
A type assertion peels away any net.OpError wrapping.
And then a second type assertion peels away any os.SyscallError wrapping.
And then the function checks the unwrapped error for equality with EADDRNOTAVAIL.
What we’ve learned from years of experience,
from this experimenting with Go errors,
is that it is very powerful to be able to define
arbitrary implementations of the error interface,
to have the full Go language available
both to construct and to deconstruct errors,
and not to require the use of any single implementation.
These properties—that errors are values, and that there is not one required error implementation—are important to preserve.
Not mandating one error implementation enabled everyone to experiment with additional functionality that an error might provide, leading to many packages, such as github.com/pkg/errors, gopkg.in/errgo.v2, github.com/hashicorp/errwrap, upspin.io/errors, github.com/spacemonkeygo/errors, and more.
One problem with unconstrained experimentation, though, is that as a client you have to program to the union of all the possible implementations you might encounter. A simplification that seemed worth exploring for Go 2 was to define a standard version of commonly-added functionality, in the form of agreed-upon optional interfaces, so that different implementations could interoperate.
Unwrap
The most commonly-added functionality in these packages is some method that can be called to remove context from an error, returning the error inside. Packages use different names and meanings for this operation, and sometimes it removes one level of context, while sometimes it removes as many levels as possible.
For Go 1.13, we have introduced a convention that an error
implementation adding removable context to an inner error
should implement an Unwrap method that returns the inner error,
unwrapping the context.
If there is no inner error appropriate to expose to callers,
either the error shouldn’t have an Unwrap method,
or the Unwrap method should return nil.
// Go 1.13 optional method for error implementations.
interface {
// Unwrap removes one layer of context,
// returning the inner error if any, or else nil.
Unwrap() error
}
The way to call this optional method is to invoke the helper function errors.Unwrap,
which handles cases like the error itself being nil or not having an Unwrap method at all.
package errors
// Unwrap returns the result of calling
// the Unwrap method on err,
// if err’s type defines an Unwrap method.
// Otherwise, Unwrap returns nil.
func Unwrap(err error) error
We can use the Unwrap method
to write a simpler, more general version of spuriousENOTAVAIL.
Instead of looking for specific error wrapper implementations
like net.OpError or os.SyscallError,
the general version can loop, calling Unwrap to remove context,
until either it reaches EADDRNOTAVAIL or there’s no error left:
func spuriousENOTAVAIL(err error) bool {
for err != nil {
if err == syscall.EADDRNOTAVAIL {
return true
}
err = errors.Unwrap(err)
}
return false
}
This loop is so common, though, that Go 1.13 defines a second function, errors.Is,
that repeatedly unwraps an error looking for a specific target.
So we can replace the entire loop with a single call to errors.Is:
func spuriousENOTAVAIL(err error) bool {
return errors.Is(err, syscall.EADDRNOTAVAIL)
}
At this point we probably wouldn’t even define the function;
it would be equally clear, and simpler, to call errors.Is directly at the call sites.
Go 1.13 also introduces a function errors.As
that unwraps until it finds a specific implementation type.
If you want to write code that works with
arbitrarily-wrapped errors,
errors.Is is the wrapper-aware
version of an error equality check:
err == target
→
errors.Is(err, target)
And errors.As is the wrapper-aware
version of an error type assertion:
target, ok := err.(*Type)
if ok {
...
}
→
var target *Type
if errors.As(err, &target) {
...
}
To Unwrap Or Not To Unwrap?
Whether to make it possible to unwrap an error is an API decision, the same way that whether to export a struct field is an API decision. Sometimes it is appropriate to expose that detail to calling code, and sometimes it isn’t. When it is, implement Unwrap. When it isn’t, don’t implement Unwrap.
Until now, fmt.Errorf has not exposed
an underlying error formatted with %v to caller inspection.
That is, the result of fmt.Errorf has not been possible to unwrap.
Consider this example:
// errors.Unwrap(err2) == nil
// err1 is not available (same as earlier Go versions)
err2 := fmt.Errorf("connect: %v", err1)
If err2 is returned to
a caller, that caller has never had any way to open up err2 and access err1.
We preserved that property in Go 1.13.
For the times when you do want to allow unwrapping the result of fmt.Errorf,
we also added a new printing verb %w, which formats like %v,
requires an error value argument,
and makes the resulting error’s Unwrap method return that argument.
In our example, suppose we replace %v with %w:
// errors.Unwrap(err4) == err3
// (%w is new in Go 1.13)
err4 := fmt.Errorf("connect: %w", err3)
Now, if err4 is returned to a caller,
the caller can use Unwrap to retrieve err3.
It is important to note that absolute rules like
“always use %v (or never implement Unwrap)” or “always use %w (or always implement Unwrap)”
are as wrong as absolute rules like “never export struct fields” or “always export struct fields.”
Instead, the right decision depends on
whether callers should be able to inspect and depend on
the additional information that using %w or implementing Unwrap exposes.
As an illustration of this point,
every error-wrapping type in the standard library
that already had an exported Err field
now also has an Unwrap method returning that field,
but implementations with unexported error fields do not,
and existing uses of fmt.Errorf with %v still use %v, not %w.
Error Value Printing (Abandoned)
Along with the design draft for Unwrap, we also published a design draft for an optional method for richer error printing, including stack frame information and support for localized, translated errors.
// Optional method for error implementations
type Formatter interface {
Format(p Printer) (next error)
}
// Interface passed to Format
type Printer interface {
Print(args ...interface{})
Printf(format string, args ...interface{})
Detail() bool
}
This one is not as simple as Unwrap,
and I won’t go into the details here.
As we discussed the design with the Go community over the winter,
we learned that the design wasn’t simple enough.
It was too hard for individual error types to implement,
and it did not help existing programs enough.
On balance, it did not simplify Go development.
As a result of this community discussion, we abandoned this printing design.
Error Syntax
That was error values. Let’s look briefly at error syntax, another abandoned experiment.
Here is some code from
compress/lzw/writer.go in the standard library:
// Write the savedCode if valid.
if e.savedCode != invalidCode {
if err := e.write(e, e.savedCode); err != nil {
return err
}
if err := e.incHi(); err != nil && err != errOutOfCodes {
return err
}
}
// Write the eof code.
eof := uint32(1)<<e.litWidth + 1
if err := e.write(e, eof); err != nil {
return err
}
At a glance, this code is about half error checks. My eyes glaze over when I read it. And we know that code that is tedious to write and tedious to read is easy to misread, making it a good home for hard-to-find bugs. For example, one of these three error checks is not like the others, a fact that is easy to miss on a quick skim. If you were debugging this code, how long would it take to notice that?
At Gophercon last year we
presented a draft design
for a new control flow construct marked by the keyword check.
Check consumes the error result from a function call or expression.
If the error is non-nil, the check returns that error.
Otherwise the check evaluates to the other results
from the call. We can use check to simplify the lzw code:
// Write the savedCode if valid.
if e.savedCode != invalidCode {
check e.write(e, e.savedCode)
if err := e.incHi(); err != errOutOfCodes {
check err
}
}
// Write the eof code.
eof := uint32(1)<<e.litWidth + 1
check e.write(e, eof)
This version of the same code uses check,
which removes four lines of code and
more importantly highlights that
the call to e.incHi is allowed to return errOutOfCodes.
Maybe most importantly, the design also allowed defining error handler blocks to be run when later checks failed. That would let you write shared context-adding code just once, like in this snippet:
handle err {
err = fmt.Errorf("closing writer: %w", err)
}
// Write the savedCode if valid.
if e.savedCode != invalidCode {
check e.write(e, e.savedCode)
if err := e.incHi(); err != errOutOfCodes {
check err
}
}
// Write the eof code.
eof := uint32(1)<<e.litWidth + 1
check e.write(e, eof)
In essence, check was a short way to write the if statement,
and handle was like
defer but only for error return paths.
In contrast to exceptions in other languages,
this design retained Go’s important property that
every potential failing call was marked explicitly in the code,
now using the check keyword instead of if err != nil.
The big problem with this design
was that handle overlapped too much,
and in confusing ways, with defer.
In May we posted
a new design with three simplifications:
to avoid the confusion with defer, the design dropped handle in favor of just using defer;
to match a similar idea in Rust and Swift, the design renamed check to try;
and to allow experimentation in a way that existing parsers like gofmt would recognize,
it changed check (now try) from a keyword to a built-in function.
Now the same code would look like this:
defer errd.Wrapf(&err, "closing writer")
// Write the savedCode if valid.
if e.savedCode != invalidCode {
try(e.write(e, e.savedCode))
if err := e.incHi(); err != errOutOfCodes {
try(err)
}
}
// Write the eof code.
eof := uint32(1)<<e.litWidth + 1
try(e.write(e, eof))
We spent most of June discussing this proposal publicly on GitHub.
The fundamental idea of check or try was to shorten
the amount of syntax repeated at each error check,
and in particular to remove the return statement from view,
keeping the error check explicit and better highlighting interesting variations.
One interesting point raised during the public feedback discussion,
however, was that without an explicit if statement and return,
there’s nowhere to put a debugging print,
there’s nowhere to put a breakpoint,
and there’s no code to show as unexecuted in code coverage results.
The benefits we were after
came at the cost of making these situations more complex.
On balance, from this as well as other considerations,
it was not at all clear that the overall result would
be simpler Go development,
so we abandoned this experiment.
That’s everything about error handling, which was one of the main focuses for this year.
Generics
Now for something a little less controversial: generics.
The second big topic we identified for Go 2 was some kind of way to write code with type parameters. This would enable writing generic data structures and also writing generic functions that work with any kind of slice, or any kind of channel, or any kind of map. For example, here is a generic channel filter:
// Filter copies values from c to the returned channel,
// passing along only those values satisfying f.
func Filter(type value)(f func(value) bool, c <-chan value) <-chan value {
out := make(chan value)
go func() {
for v := range c {
if f(v) {
out <- v
}
}
close(out)
}()
return out
}
We’ve been thinking about generics since work on Go began,
and we wrote and rejected our first concrete design in 2010.
We wrote and rejected three more designs by the end of 2013.
Four abandoned experiments,
but not failed experiments,
We learned from them,
like we learned from check and try.
Each time, we learned that the path to Go 2 is not in that exact direction,
and we noticed other directions that might be interesting to explore.
But by 2013 we had decided that we needed to focus on other concerns,
so we put the entire topic aside for a few years.
Last year we started exploring and experimenting again, and we presented a new design, based on the idea of a contract, at Gophercon last summer. We’ve continued to experiment and simplify, and we’ve been working with programming language theory experts to understand the design better.
Overall, I am hopeful that we’re headed in a good direction, toward a design that will simplify Go development. Even so, we might find that this design doesn’t work either. We might have to abandon this experiment and adjust our path based on what we learned. We’ll find out.
At Gophercon 2019, Ian Lance Taylor talked about why we might want to add generics to Go and briefly previewed the latest design draft. For details, see his blog post “Why Generics?”
Dependencies
The third big topic we identified for Go 2 was dependency management.
In 2010 we published a tool called goinstall,
which we called
“an experiment in package installation.”
It downloaded dependencies and stored them in your
Go distribution tree, in GOROOT.
As we experimented with goinstall,
we learned that the Go distribution and the installed packages
should be kept separate,
so that it was possible to change to a new Go distribution
without losing all your Go packages.
So in 2011 we introduced GOPATH,
an environment variable that specified
where to look for packages not found in the main Go distribution.
Adding GOPATH created more places for Go packages but simplified Go development overall, by separating your Go distribution from your Go libraries.
Compatibility
The goinstall experiment intentionally left out
an explicit concept of package versioning.
Instead, goinstall always downloaded the latest copy.
We did this so we could focus on the other
design problems for package installation.
Goinstall became go get as part of Go 1.
When people asked about versions,
we encouraged them to experiment by
creating additional tools, and they did.
And we encouraged package authors
to provide their users
with the same backwards compatibility
we did for the Go 1 libraries.
Quoting the Go FAQ:
“Packages intended for public use should try to maintain backwards compatibility as they evolve.
If different functionality is required, add a new name instead of changing an old one.
If a complete break is required, create a new package with a new import path.”
This convention simplifies the overall experience of using a package by restricting what authors can do: avoid breaking changes to APIs; give new functionality a new name; and give a whole new package design a new import path.
Of course, people kept experimenting.
One of the most interesting experiments
was started by Gustavo Niemeyer.
He created a Git redirector called
gopkg.in,
which provided different import paths
for different API versions,
to help package authors
follow the convention
of giving a new package design
a new import path.
For example,
the Go source code in the GitHub repository
go-yaml/yaml
has different APIs
in the v1 and v2 semantic version tags.
The gopkg.in server provides these with
different import paths
gopkg.in/yaml.v1
and
gopkg.in/yaml.v2.
The convention of providing backwards compatibility,
so that a newer version of a package can be used
in place of an older version,
is what makes go get’s very simple rule—“always download the latest copy”—work well even today.
Versioning And Vendoring
But in production contexts you need to be more precise about dependency versions, to make builds reproducible.
Many people experimented with what that should look like,
building tools that served their needs,
including Keith Rarick’s goven (2012) and godep (2013),
Matt Butcher’s glide (2014), and Dave Cheney’s gb (2015).
All of these tools use the model that you copy dependency
packages into your own source control repository.
The exact mechanisms used
to make those packages available for import varied,
but they were all more complex than it seemed they should be.
After a community-wide discussion,
we adopted a proposal by Keith Rarick
to add explicit support for referring to copied dependencies
without GOPATH tricks.
This was simplifying by reshaping:
like with addToList and append,
these tools were already implementing the concept,
but it was more awkward than it needed to be.
Adding explicit support for vendor directories
made these uses simpler overall.
Shipping vendor directories in the go command
led to more experimentation with vendoring itself,
and we realized that we had introduced a few problems.
The most serious was that we lost package uniqueness.
Before, during any given build,
an import path
might appear in lots of different packages,
and all the imports referred to the same target.
Now with vendoring, the same import path in different
packages might refer to different vendored copies of the package,
all of which would appear in the final resulting binary.
At the time, we didn’t have a name for this property: package uniqueness. It was just how the GOPATH model worked. We didn’t completely appreciate it until it went away.
There is a parallel here with the check and try
error syntax proposals.
In that case, we were relying
on how the visible return statement worked
in ways we didn’t appreciate
until we considered removing it.
When we added vendor directory support,
there were many different tools for managing dependencies.
We thought that a clear agreement
about the format of vendor directories
and vendoring metadata
would allow the various tools to interoperate,
the same way that agreement about
how Go programs are stored in text files
enables interoperation
between the Go compiler, text editors,
and tools like goimports and gorename.
This turned out to be naively optimistic. The vendoring tools all differed in subtle semantic ways. Interoperation would require changing them all to agree about the semantics, likely breaking their respective users. Convergence did not happen.
Dep
At Gophercon in 2016, we started an effort
to define a single tool to manage dependencies.
As part of that effort, we conducted surveys
with many different kinds of users
to understand what they needed
as far as dependency management,
and a team started work on a new tool,
which became dep.
Dep aimed to be able to replace all the
existing dependency management tools.
The goal was to simplify by reshaping the
existing different tools into a single one.
It partly accomplished that.
Dep also restored package uniqueness for its users,
by having only one vendor directory
at the top of the project tree.
But dep also introduced a serious problem
that took us a while to fully appreciate.
The problem was that dep embraced a design choice from glide,
to support and encourage incompatible changes to a given package
without changing the import path.
Here is an example. Suppose you are building your own program, and you need to have a configuration file, so you use version 2 of a popular Go YAML package:
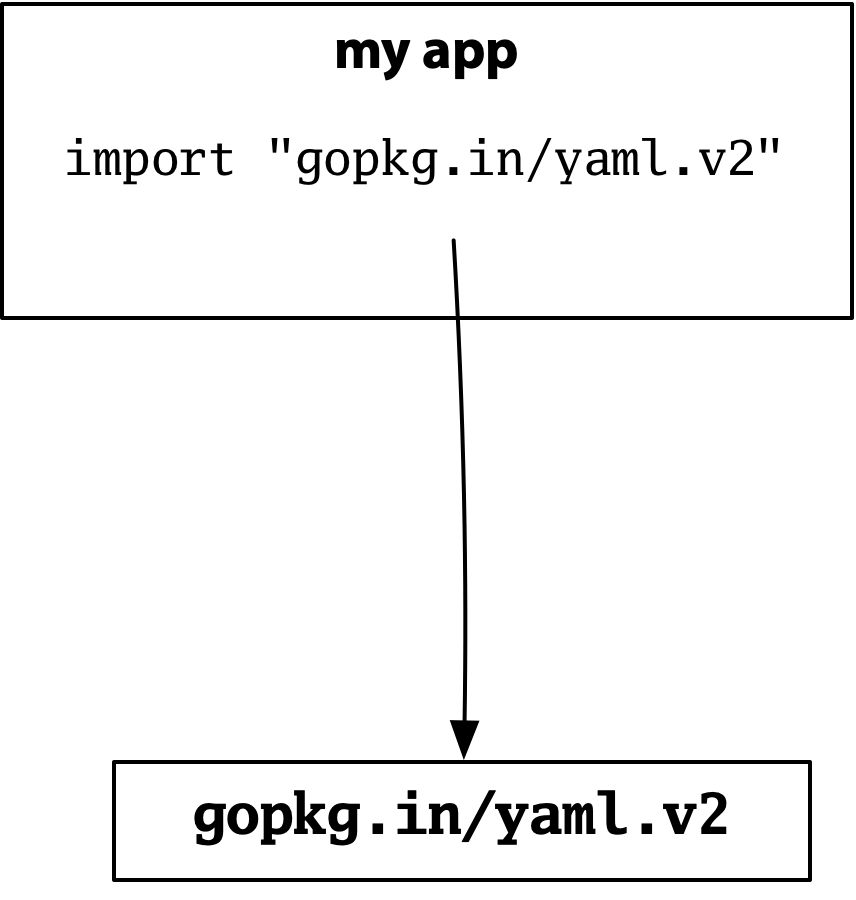
Now suppose your program imports the Kubernetes client. It turns out that Kubernetes uses YAML extensively, and it uses version 1 of the same popular package:
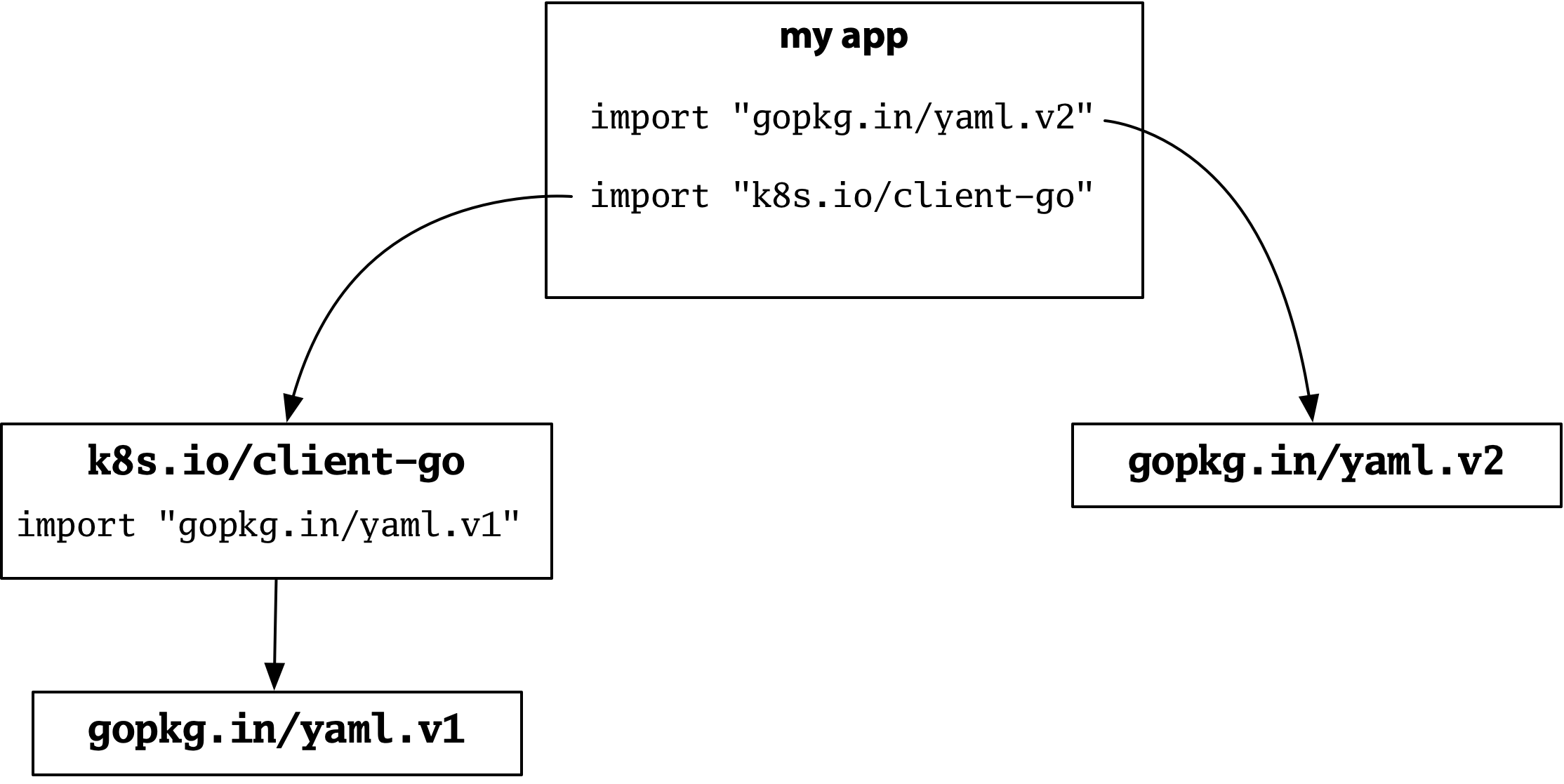
Version 1 and version 2 have incompatible APIs, but they also have different import paths, so there is no ambiguity about which is meant by a given import. Kubernetes gets version 1, your config parser gets version 2, and everything works.
Dep abandoned this model.
Version 1 and version 2 of the yaml package would now
have the same import path,
producing a conflict.
Using the same import path for two incompatible versions,
combined with package uniqueness,
makes it impossible to build this program
that you could build before:
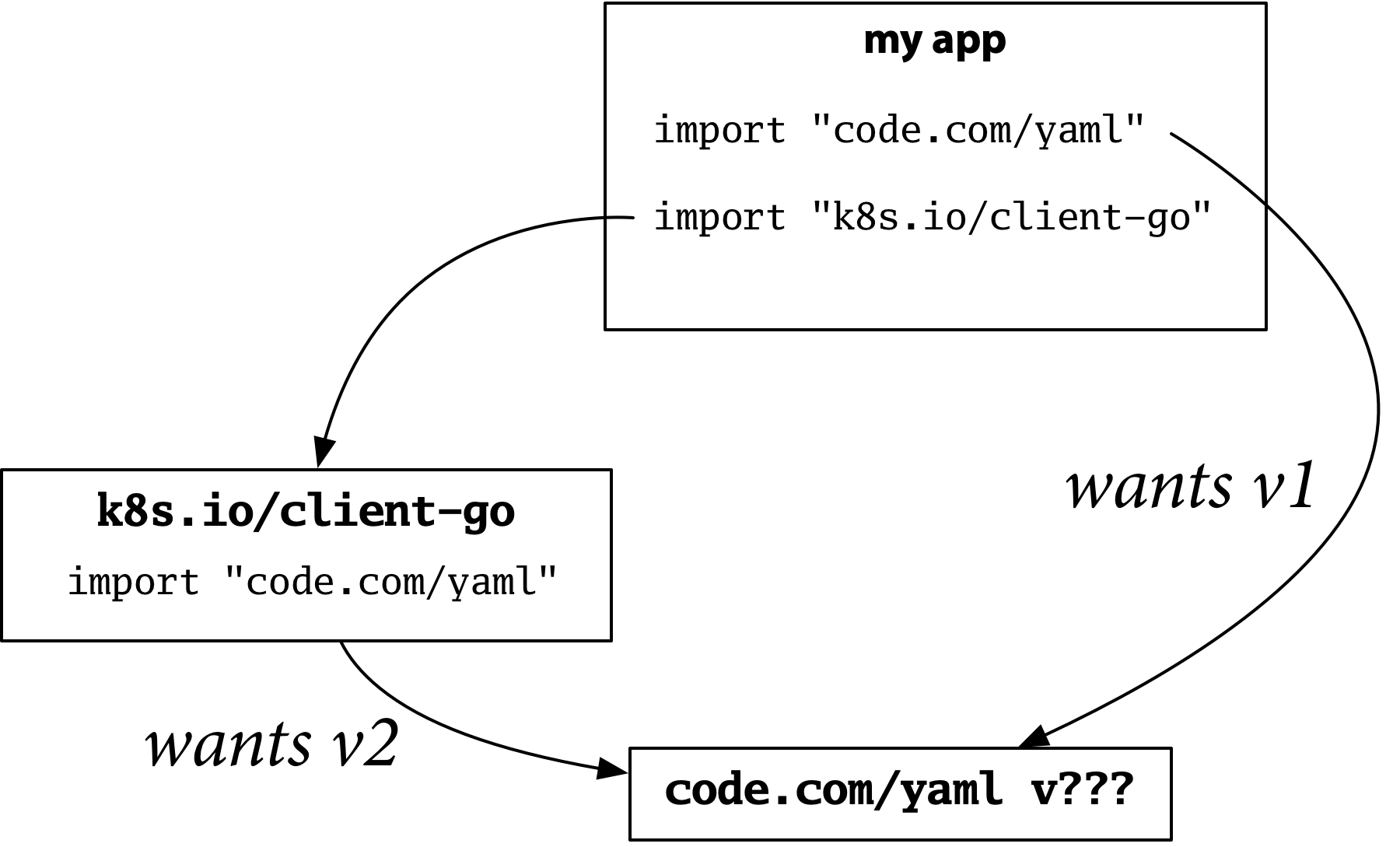
It took us a while to understand this problem, because we had been applying the “new API means new import path” convention for so long that we took it for granted. The dep experiment helped us appreciate that convention better, and we gave it a name: the import compatibility rule:
“If an old package and a new package have the same import path, the new package must be backwards compatible with the old package.”
Go Modules
We took what worked well in the dep experiment
and what we learned about what didn’t work well,
and we experimented with a new design, called vgo.
In vgo, packages followed the import compatibility rule,
so that we can provide package uniqueness
but still not break builds like the one we just looked at.
This let us simplify other parts of the design as well.
Besides restoring the import compatibility rule,
another important part of the vgo design
was to give the concept of a group of packages a name
and to allow that grouping to be separated
from source code repository boundaries.
The name of a group of Go packages is a module,
so we refer to the system now as Go modules.
Go modules are now integrated with the go command,
which avoids needing to copy around vendor directories at all.
Replacing GOPATH
With Go modules comes the end of GOPATH as a global name space. Nearly all the hard work of converting existing Go usage and tools to modules is caused by this change, from moving away from GOPATH.
The fundamental idea of GOPATH is that the GOPATH directory tree is the global source of truth for what versions are being used, and the versions being used don’t change as you move around between directories. But the global GOPATH mode is in direct conflict with the production requirement of per-project reproducible builds, which itself simplifies the Go development and deployment experience in many important ways.
Per-project reproducible builds means that
when you are working in a checkout of project A,
you get the same set of dependency versions that the other developers of project A get
at that commit,
as defined by the go.mod file.
When you switch to working in a checkout of project B,
now you get that project’s chosen dependency versions,
the same set that the other developers of project B get.
But those are likely different from project A.
The set of dependency versions
changing when you move from project A to project B
is necessary to keep your development in sync
with that of the other developers on A and on B.
There can’t be a single global GOPATH anymore.
Most of the complexity of adopting modules arises directly from the loss of the one global GOPATH. Where is the source code for a package? Before, the answer depended only on your GOPATH environment variable, which most people rarely changed. Now, the answer depends on what project you are working on, which may change often. Everything needs updating for this new convention.
Most development tools use the
go/build package to find and load Go source code.
We’ve kept that package working,
but the API did not anticipate modules,
and the workarounds we added to avoid API changes
are slower than we’d like.
We’ve published a replacement,
golang.org/x/tools/go/packages.
Developer tools should now use that instead.
It supports both GOPATH and Go modules,
and it is faster and easier to use.
In a release or two we may move it into the standard library,
but for now golang.org/x/tools/go/packages
is stable and ready for use.
Go Module Proxies
One of the ways modules simplify Go development is by separating the concept of a group of packages from the underlying source control repository where they are stored.
When we talked to Go users about dependencies,
almost everyone using Go at their companies
asked how to route go get package fetches
through their own servers,
to better control what code can be used.
And even open-source developers were concerned
about dependencies disappearing
or changing unexpectedly,
breaking their builds.
Before modules, users had attempted
complex solutions to these problems,
including intercepting the version control
commands that the go command runs.
The Go modules design makes it easy to introduce the idea of a module proxy that can be asked for a specific module version.
Companies can now easily run their own module proxy, with custom rules about what is allowed and where cached copies are stored. The open-source Athens project has built just such a proxy, and Aaron Schlesinger gave a talk about it at Gophercon 2019. (We’ll add a link here when the video becomes available.)
And for individual developers and open source teams, the Go team at Google has launched a proxy that serves as a public mirror of all open-source Go packages, and Go 1.13 will use that proxy by default when in module mode. Katie Hockman gave a talk about this system at Gophercon 2019.
Go Modules Status
Go 1.11 introduced modules as an experimental, opt-in preview. We keep experimenting and simplifying. Go 1.12 shipped improvements, and Go 1.13 will ship more improvements.
Modules are now at the point where we believe that they will serve most users, but we aren’t ready to shut down GOPATH just yet. We will keep experimenting, simplifying, and revising.
We fully recognize that the Go user community built up almost a decade of experience and tooling and workflows around GOPATH, and it will take a while to convert all of that to Go modules.
But again, we think that modules will now work very well for most users, and I encourage you to take a look when Go 1.13 is released.
As one data point, the Kubernetes project has a lot of dependencies, and they have migrated to using Go modules to manage them. You probably can too. And if you can’t, please let us know what’s not working for you or what’s too complex, by filing a bug report, and we will experiment and simplify.
Tools
Error handling, generics, and dependency management are going to take a few more years at least, and we’re going to focus on them for now. Error handling is close to done, modules will be next after that, and maybe generics after that.
But suppose we look a couple years out, to when we are done experimenting and simplifying and have shipped error handling, modules, and generics. Then what? It’s very difficult to predict the future, but I think that once these three have shipped, that may mark the start of a new quiet period for major changes. Our focus at that point will likely shift to simplifying Go development with improved tools.
Some of the tool work is already underway, so this post finishes by looking at that.
While we helped update all the Go community’s existing tools to understand Go modules, we noticed that having a ton of development helper tools that each do one small job is not serving users well. The individual tools are too hard to combine, too slow to invoke, and too different to use.
We began an effort to unify the most commonly-required
development helpers into a single tool,
now called gopls (pronounced “go, please”).
Gopls speaks the
Language Server Protocol, LSP,
and works with any integrated development environment
or text editor with LSP support,
which is essentially everything at this point.
Gopls marks an expansion in focus for the Go project,
from delivering standalone compiler-like, command-line
tools like go vet or gorename
to also delivering a complete IDE service.
Rebecca Stambler gave a talk with more details about gopls and IDEs at Gophercon 2019.
(We’ll add a link here when the video becomes available.)
After gopls, we also have ideas for reviving go fix in an
extensible way and for making go vet even more helpful.
Coda
So there’s the path to Go 2.
We will experiment and simplify.
And experiment and simplify.
And ship.
And experiment and simplify.
And do it all again.
It may look or even feel like the path goes around in circles.
But each time we experiment and simplify
we learn a little more about what Go 2 should look like
and move another step closer to it.
Even abandoned experiments like try
or our first four generics designs
or dep are not wasted time.
They help us learn what needs to be
simplified before we can ship,
and in some cases they help us better understand
something we took for granted.
At some point we will realize we have experimented enough, and simplified enough, and shipped enough, and we will have Go 2.
Thanks to all of you in the Go community for helping us experiment and simplify and ship and find our way on this path.
Next article: Contributors Summit 2019
Previous article: Why Generics?
Blog Index